Les saisons de la Garonne vues par ses hauteurs d'eau
La Garonne est l'un des cinq grands fleuves français. Elle part des Pyrénées vers le nord, passe par Toulouse et tourne ensuite vers l'ouest, passe à Bordeaux pour enfin rejoindre l'océan Atlantique entre la pointe du Médoc et Royan. C'est un fleuve assez aménagé par l'être humain mais qui connaît quand même des variations d'une saison sur l'autre. Les pluies hivernales et la fonte des neiges printanière le font monter, tandis que la sécheresse estivale le fait baisser. Montée ou baisse sont l'une comme l'autre plus ou moins importantes selon les années. Les satellites qui permettent de mesurer la hauteur des océans sont aussi capables de mesurer le niveau des rivières et des fleuves qu'ils survolent, si ceux-ci sont assez larges. Le site Argonautica propose de telles mesures, sur des rivières et des fleuves, et également sur des lacs choisis pour des projets. Par analogie avec des stations de mesure "in situ" (sur place), les points où on peut avoir ce type de mesure sont appelées des "stations virtuelles" (virtuelles car il n'y a rien d'installé sur place).
Localiser les stations virtuelles sur une carte
Nous allons tracer et analyser la courbe des variations de ce niveau en plusieurs points du fleuve. Les points que l'on retient sont ceux qui ont été récemment mis à jour, soit les points ...
Python : tracer ces points sur une carte (Folium sur fond OpenStreetMap)
on utilise le fichier sv_bassin-garonne_locs.txt, à télécharger et mettre dans le même répertoire que le programme Python. Un fichier équivalent peut être fait à partir de toutes les autres "stations" ou des lacs, il suffit d'un nom, de la longitude et de la latitude.
import pandas import folium |
Importe la libraire Pandas, qui permet de lire le fichier
Importe la libraire Folium, qui permet de faire une carte en ligne |
infile = 'sv_bassin-garonne_locs.txt' indata = pandas.read_csv(infile, sep='\t', skiprows=1, names=['nom', 'lon', 'lat']) |
# ingestion des données ;
# à noter : # le séparateur (sep) est une tabulation (\t) # on saute la première ligne qui contient les en-têtes des colonnes, pas des valeurs (skiprows) # ensuite, on définit les différentes colonnes pour pouvoir les appeler ensuite |
centre_longitude = 1. centre_latitude = 44. |
# définition du centre de la carte telle qu'elle apparaîtra à l'écran -- attention, ces valeurs dépendent de la zone choisie |
macarte=folium.Map(location=[centre_latitude,centre_longitude],zoom_start=7)
# on cherche le nombre de lignes du fichier
nb_lignes = len(indata)
#on créé un tableau vide, dans lequel on va ajouter les points
points = []
# on trace un marqueur pour toutes les lignes une à une avec i qui va de 0 à nb_lignes, de 1 en 1
for i in range(0,nb_lignes):
folium.Marker(location=[indata['lat'][i],indata['lon'][i]]).add_to(macarte)
points.append(tuple([indata['lat'][i], indata['lon'][i]]))
|
On définit la carte que l'on va utiliser ensuite (map)
# tracé de *_toutes_* les localisations présentes dans le fichier sous forme de marqueurs |
map.save("./carte_stations.html") |
# le résultat est sauvé dans un fichier html, à ouvrir avec un navigateur web (connecté à Internet pour avoir les continents) |
)
La carte produite par ce programme
Nous les avons choisis parmi la douzaine possible car ils sont mis à jour encore aujourd'hui (mai 2020), et devraient l'être encore quelques temps. La même analyse peut se faire sur les autres points possibles, mais les mesures datent de plus longtemps et ne sont plus mises à jour car le satellite qui prenait ces mesures s'est arrêté. Ci-dessous les courbes telles qu'elles apparaissent sur le site Argonautica, du point le plus en amont (le plus proche des montagnes, noté km228) au point le plus en aval (le plus proche de l'embouchure, km163)
)
Hauteurs d'eau satellite à la "station km 228" (credit Hydroweb)
)
Hauteurs d'eau satellite à la "station km 195" (credit Hydroweb)
)
Hauteurs d'eau satellite à la "station km 194" (credit Hydroweb)
)
Hauteurs d'eau satellite à la "station km 191" (credit Hydroweb)
)
Hauteurs d'eau satellite à la "station km 163" (credit Hydroweb)
À l'oeil, on voit quelques pics ou creux de la courbe qui se ressemblent. On voit aussi plus ou moins selon les "stations" une sorte de régularité : les "pics" et les "creux" sont toujours à peu près aux mêmes moments de l'année, même s'ils peuvent être plus ou moins forts selon les années et les "stations".
Tracer la courbe de la hauteur d'eau en fonction du temps
Si vous ouvrez l'un des fichiers txt fournis avec un éditeur de texte simple (notepad, bloc note). Vous verrez les 2 premières lignes. Celles-ci sont des informations sur la mesure ; on parle d'entête de fichier. Pour tracer, nous commenceront après ces lignes. Ensuite, vous avez 4 colonnes. Ce qu'elles contiennent est notamment décrit dans les 2 premières lignes : la date, l'heure, la hauteur mesurée, l'erreur sur cette mesure (fin de la ligne), le tout séparé par des tabulations.
L'erreur est une estimation de la qualité de la mesure. Plus elle est élevée plus on doute de la mesure. C'est ce qui est représenté par les traits rouges verticaux sur les courbes ci-dessus. On notera en particulier que plus la hauteur d'eau est faible, bien souvent plus cette erreur est élevée : il y a moins de surface d'eau sur laquelle le satellite peut mesurer, donc on est moins sûr de la valeur obtenue.
(pour des fichiers sur rivière et fleuve directement issus du site Hydroweb, compter 33 lignes d'entête ; le reste est identique)
Tableur (MSExcel, OpenOffice Calc)
On peut tracer ces données en utilisant un logiciel tableur.
- Avec Excel : Ouvrir le logiciel. Faire fichier > Ouvrir ; choisir 'tous les fichiers' (et non pas seulement les .xsls) pour voir aussi les fichiers .txt
Une fenêtre 'assistant d'importation de texte' s'ouvre.
Choisir 'délimité', indiquer 3 comme ligne à partir de laquelle commencer l'importation, et cliquer sur 'mes données ont des entêtes'. Puis cliquer sur le bouton "suivant".
Choisir 'tabulation' dans les séparateurs. Puis cliquer sur le bouton "suivant".
Dans la troisième fenêtre, cliquer sur la 1e colonne en bas et cocher la case "Date" plus haut, en choisissant AMJ dans le menu déroulant (soit : Année mois jour). Cliquer sur les 3e et 4e colonnes, et appuyer sur le bouton "avancé". Changer le "séparateur de décimale" pour "." au lieu de "," et décocher la case "signe moins à la fin des nombres négatifs".
Cliquer sur le bouton "terminé". - Avec Calc : clic-droit sur le fichier, "Ouvrir avec", choisir OpenOffice Calc (sinon, le fichier s'ouvrira sur Open Office Writer)
Une fenêtre 'Import de texte' s'ouvre.
Dans les "Options de séparateur", choisir "tabulation".
Dans les "Champs", cliquer sur la colonne des dates en bas et choisir Date (AMJ) dans le menu "Type de colonne". Cliquer sur la colonne C. et choisir Anglais US. Même chose pour la colonne D, et cliquer sur OK.
Il reste encore une manipulation à ce stade :
- Définir la colonne des heures dans un format adapté : clic-droit sur la colonne entière, choisir 'format de cellule' (Formatter cellules sous Calc). Mettre un format heure à l'heure (choisir un format sans les secondes – le 2e dans la liste Excel, le 1er dans la liste Calc)
Pour tracer une courbe à partir de cela, il faut sélectionner la colonne des dates (idéalement, il faudrait créer une colonne "A+B" pour avoir date et heure) et celle des hauteurs. Aller dans le menu Insertion, et cliquer sur insérer un graphe en courbe ou en aire, et ensuite une des "courbes 2D", soit "courbe" soit "courbe avec marques". Avec ce dernier, on a :
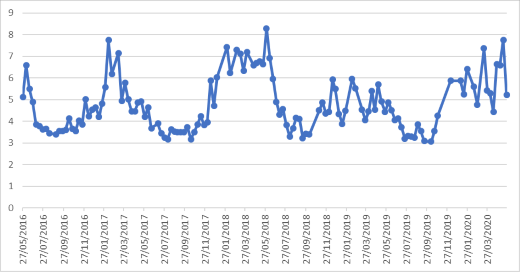
La courbe produite par le tableur
Python
import pandas |
Importe la libraire Pandas, qui permet de lire le fichier |
infile = 'R_GARONNE_GARONNE_KM0163.txt' indata = pandas.read_csv(infile, sep=' ', skiprows=2, names=['date', 'heure', 'hauteur', 'erreur']) |
Le nom du fichier (entre ' ')
Permet de lire et d'avoir en mémoire le tableau des données et ce de façon à pouvoir appeler ensuite les colonnes par un nom # le séparateur (sep) entre les colonnes de données est un espace (' ') # on saute les 2 premières lignes qui contiennent les en-têtes des colonnes (skiprows) # ensuite, on définit les noms (names) des différentes colonnes, pour pouvoir les appeler ensuite |
indatavalid = indata[(indata['erreur'] < 9999)] |
Certaines mesures réalisées sont fausses ; une valeur de 9999 les indique. On ne garde que les lignes qui sont en-dessous strictement de cette valeur, et on stocke dans "intadatavalid". |
indatavalid['date_interpretee'] = pandas.to_datetime((indatavalid['date'] + ' ' + indatavalid['heure']), format='%Y-%m-%d %H:%M') |
Les données lues dans le tableau sont interprétées comme des chaînes de caractères, c'est-à-dire une suite de caractères (lettres, signes de ponctuation, chiffres…) ou éventuellement comme des nombres. Les dates et heures incluent des - et des : et sont considérées comme des chaînes de caractères par le langage Python. Si on veut utiliser la date et l'heure, il faut que le programme les interprète comme des dates et heures. Et indiquer le format de dates et heure utilisé. |
indatavalid.plot.line(x= 'date_interpretee', y='hauteur', yerr='erreur', capsize=3, ecolor='red') |
On trace (plot) sous forme de ligne (line) avec date_interprétée en abscisse (x) et hauteur en ordonnée (y). Facultatif : on peut définir l'erreur sur l'ordonnée (yerr) égale à "erreur", qui sera alors tracée comme une droite verticale de la longueur indiquée de part et d'autre du point, avec par exemple un trait qui la "chapeaute" (cap), d'une taille (size) de 3. On peut colorer ces barres d'erreur (ecolor) en rouge(red). |
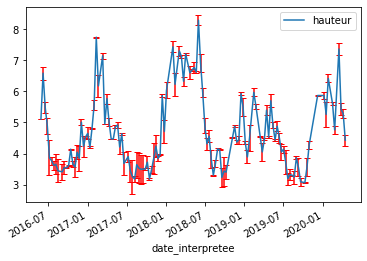
La courbe produite par ce programme
Obtenir les valeurs minimales et maximales, et les dates de celles-ci
Station par station, on peut extraire des données les valeurs minimales (quand le fleuve est le plus "à sec"), maximales (quand il est au plus haut, peut-être même en crue), et les dates de celles-ci.
Tableur (MSExcel, OpenOffice Calc)
Sous Excel, choisir deux cases vides à droite du tableau.
Dans la première, on entrera la formule " =max(C:C)" qui affichera le maximum de la colonne C (des hauteurs).
Dans la seconde, "=INDEX(A:A;EQUIV(MAX(C:C);C:C;0))", qui donnera la valeur dans la colonne A (date) de la ligne où la hauteur (colonne C) est égale à son maximum.
Python
import pandas |
Importe la libraire Pandas, qui permet de lire le fichier |
infile = 'R_GARONNE_GARONNE_KM0163.txt' indata = pandas.read_csv(infile, sep=' ', skiprows=2, names=['date', 'heure', 'hauteur', 'erreur']) |
Le nom du fichier (entre ' ')
Permet de lire et d'avoir en mémoire le tableau des données et ce de façon à pouvoir appeler ensuite les colonnes par un nom # le séparateur (sep) entre les colonnes de données est un espace (' ') # on saute les 2 premières lignes qui contiennent les en-têtes des colonnes (skiprows) # ensuite, on définit les noms (names) des différentes colonnes, pour pouvoir les appeler ensuite |
indatavalid = indata[(indata['erreur'] < 9999)] |
Certaines mesures réalisées sont fausses ; une valeur de 9999 les indique. On ne garde que les lignes qui sont en-dessous strictement de cette valeur, et on stocke dans "intadatavalid". |
hmax = indatavalid['hauteur'].max() hmin = indatavalid['hauteur'].min() |
On recherche le maximum (max) et le minimum de la colonne 'hauteur'. On les stocke en mémoire sous le nom de hmax et hmin |
minligne = indatavalid[(indatavalid['hauteur'] == hmin)] maxligne = indatavalid[(indatavalid['hauteur'] == hmax)] |
On recherche les lignes où les hauteurs sont égales à ces valeurs hmin et hmax, car on veut aussi savoir à quelle date cela s'est produit. |
print("la valeur min est", hmin, "à la date", minligne['date_interpretee'].values)
print("la valeur max est", hmax, "à la date", maxligne['date_interpretee'] .values)
|
On affiche à l'écran les hauteurs min et max, et la date/heure à laquelle elles ont été mesurées |
indatavalid['annee'] = pandas.DatetimeIndex(indatavalid['date']).year max_par_annee = indatavalid.groupby(indatavalid['annee'])['hauteur'].max() print(max_par_annee) |
On ajoute une colonne "année" Et on regarde le maximum par année (vous pouvez essayer également le minimum) |
Les maximum/minimum avec la date donnent une indication de la saisonnalité des variations de hauteur. Les maximum/minimum par années montrent les amplitudes et les variations d'une année sur l'autre. Maintenant, il est aussi intéressant de regarder à quelle date (mois) sont ces minima et maxima. Nous allons le faire graphiquement.
Regarder les tendances mensuelles
Pour regarder les variations de la hauteur du fleuve à chaque station mensuellement, on va faire la moyenne par mois de toutes les hauteurs ayant été mesurées ce mois-là, et ensuite tracer ces moyennes en fonction du mois.
Tableur (MSExcel, OpenOffice Calc)
Pour connaître la moyenne par mois des hauteurs, on va commencer par déterminer à quel mois chaque hauteur a été mesurée. Pour cela, on utilise la formule "=(MOIS(A1)" par exemple en colonne G, appliquée à toutes les lignes du tableau. On crée ensuite un second tableau (dans une autre feuille, ou sur la même plus à droite) avec de 1 à 12 sur la première colonne (mettons la colonne I), et la formule "=MOYENNE.SI(G:G ;{I1 à I12};C:C)", qui va parcourir la colonne G, pour tester si ce qui s'y trouve est égal à l'un des douze nombre entrés de I1 à I12, et quand c'est le cas, utiliser le nombre présent dans la colonne C pour la moyenne. Il ne reste plus alors qu'à tracer la courbe, comme précédemment.
Python
import pandas |
Importe la libraire Pandas, qui permet de lire le fichier |
infile = 'R_GARONNE_GARONNE_KM0163.txt' indata = pandas.read_csv(infile, sep=' ', skiprows=2, names=['date', 'heure', 'hauteur', 'erreur']) |
Le nom du fichier (entre ' ')
Permet de lire et d'avoir en mémoire le tableau des données et ce de façon à pouvoir appeler ensuite les colonnes par un nom # le séparateur (sep) entre les colonnes de données est un espace (' ') # on saute les 2 premières lignes qui contiennent les en-têtes des colonnes (skiprows) # ensuite, on définit les noms (names) des différentes colonnes, pour pouvoir les appeler ensuite |
indatavalid = indata[(indata['erreur'] < 9999)] |
Certaines mesures réalisées sont fausses ; une valeur de 9999 les indique. On ne garde que les lignes qui sont en-dessous strictement de cette valeur, et on stocke dans "intadatavalid". |
indatavalid['date-endate'] = pandas.to_datetime((indatavalid['date']), format='%Y-%m-%d') indatavalid['mois'] = pandas.DatetimeIndex(indatavalid['endate']).month |
Les données lues dans le tableau sont interprétées comme des chaînes de caractères, c'est-à-dire une suite de caractères (lettres, signes de ponctuation, chiffres…) ou éventuellement comme des nombres. Les dates et heures incluent des - et des : Ici, on ne va utiliser que la date (pas l'heure), et extraire le mois |
h_par_mois = indatavalid.groupby(indatavalid['mois']).mean() print(h_par_mois['hauteur']) |
On calcule la moyenne (mean) en ayant groupé par mois les données. On affiche à l'écran les résultats |
# tracé de cette moyenne h_par_mois.plot.line(x='mois', y='hauteur') |
On trace cette moyenne sous forme de courbe de la hauteur en fonction du mois (de 1 à 12) |
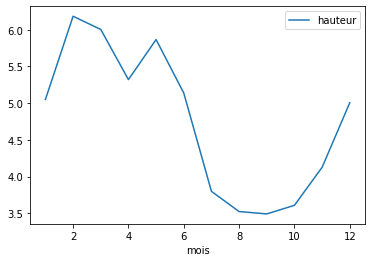
La courbe produite par ce programme
Comparaison avec la quantité de pluie
On trouve sur le site de Météo France des données "climat", qui donnent des moyennes sur 30 ans, notamment de la quantité de pluie (précipitations). (https://meteofrance.com/climat/normales/france/occitanie/ pour la région Occitanie) Par exemple, sur la ville de Toulouse, qui se trouve très en amont de notre point "km228".
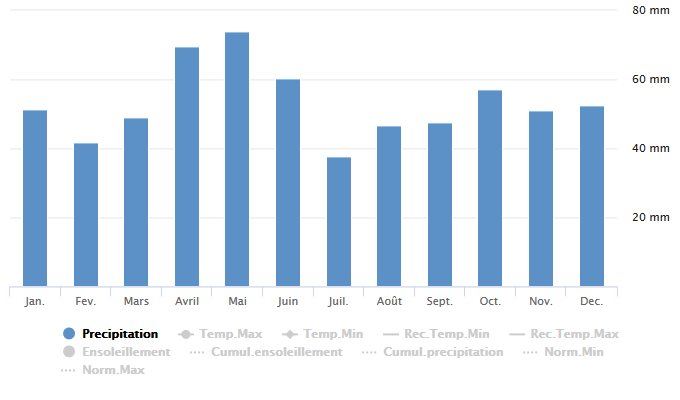
L'histogramme disponible en 2019 sur le site de Météo France pour la période 1981-2010 (une mise à jour de la période de référence fait que les données sont légèrement différentes aujourd'hui, de 1991 à 2020) (crédit Météo France)
Un histogramme est montré sur le site de Météo France, mais on peut également en tracer un.
Récupération et mise en forme des données
Sous un tableur, il suffit de copier le tableau sur le site (cliquer sur l'icône en haut à droite du titre), et de le coller dans un fichier vide.
En Python, attention à mettre des points à la place des virgules dans les chiffres, et à ne pas garder les noms de mois en français si vous voulez les utiliser comme des mois dans une date – vous pouvez les garder comme des mots mais listez-les alors surtout dans le bon ordre).
Dans les deux cas, supprimer les unités de la grandeur que vous voulez représenter.
Tracé
Tableur (MSExcel, OpenOffice Calc)
Copier-coller les données du tableau de Météo France dans le tableur. Choisir la colonne mois et précipitation, supprimer les unités de la colonne des données (qui ne seront pas reconnues comme des nombres sinon), et insérer un graphe, par exemple un histogramme.
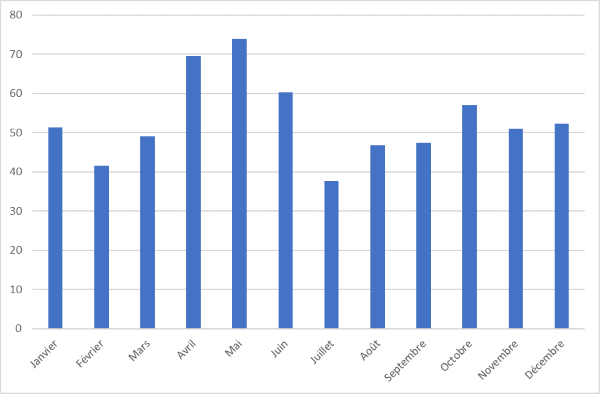
L'histogramme produit
Python
On a juste gardé deux colonnes, une avec les n° des mois, l'autre avec les hauteurs de précipitations en notation décimale anglaise (. au lieu de ,), sans l'unité. Pour mémoire, ce sont des mm.
import pandas |
On utilise toujours la même librairie |
infile = 'climato_toulouse.txt' indata = pandas.read_csv(infile, sep='\t', names=['mois', 'precipitations']) |
On a écrit un fichier avec des noms ou des numéros de mois, une tabulation, et la hauteur de précipitations ; pas d'entête (on pourrait). |
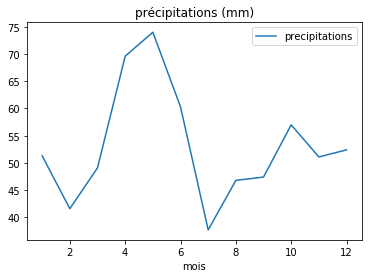
indata.plot.line(x='mois', y='precipitations' , title='précipitations (mm)) |
On trace une courbe des précipitations en fonction du mois. On met ce dont il s'agit et l'unité dans le titre. Si vous préférez un histogramme pour avoir le même type de graphe que Météo France, mettre 'bar' au lieu de 'line' (indata.plot.bar(…) ). |
 |
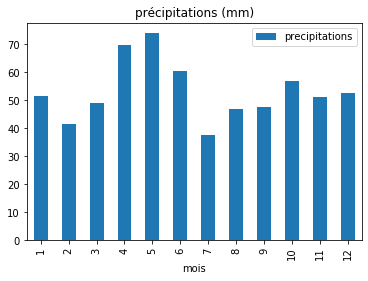 |
Les deux types de graphes ; à noter que l'échelle en ordonnées de la courbe ne débute pas à 0, contrairement à celle de l'histogramme.
Analyse
On retrouve le pic de mai, et le creux de fin d'été, mais de toute évidence, il y a des différences entre les moyennes mensuelles des précipitations sur 30 ans (1981-2010) à Toulouse et celles de hauteur de la Garonne sur 5 ans (2016-2020) en février. Ceci peut être dû à plusieurs facteurs : d'une part, il peut pleuvoir plus en aval de Toulouse qu'à Toulouse même, et la Garonne montera (regardez les statistiques de précipitations de Montauban, Agen et Bordeaux, plus proches des points de mesure de hauteur). Par ailleurs, toute l'eau de la Garonne ne vient pas des pluies, mais vient aussi de la neige et de sa fonte. De plus, le Tarn par exemple vient grossir les eaux de la Garonne à Moissac, en amont de Montauban. Le Lot s'ajoute ensuite, peu après le point 228 km, et la Dordogne au niveau de Bordeaux. Ces rivières peuvent être issues d'une région où il a particulièrement plu, alors que la pluie sur Toulouse n'a pas été très importante. Enfin, les périodes utilisées ne sont pas les mêmes, ni en termes de dates (1981-2010 contre 2016-2020), ni surtout de longueur. Or, s'il se trouve une ou plusieurs années inhabituelles dans les 5 ans de mesure satellite du niveau de la Garonne, cela faussera les tendances ; c'est pourquoi on utilise des périodes longues comme 30 ans pour calculer ce type de tendances (on parle de climatologie ou de moyennes climatiques), ce qui a pour effet de gommer l'impact d'évènements forts. On pourrait utiliser des mesures très proches réalisées avec d'autres satellites sur des périodes antérieures (2002-2010 ou 2008-2017) pour obtenir une statistique plus juste.
Regarder les variations d'une année sur l'autre
Tracer les années une par une sur la même figure, pour voir les tendances similaires (saisonnières), et les écarts que l'on observe d'une année sur l'autre.
Tableur (MSExcel, OpenOffice Calc)
On reprend le même fichier que précédemment. Il va falloir une abscisse commune si l'on veut que les courbes se superposent. Pour cela, on va utiliser le numéro du jour dans l'année (on parle de 'quantième'). On le calcule dans une nouvelle colonne, plutôt à gauche de la colonne de la hauteur cette fois (faire insérer une colonne). Là, on utilise la formule "=A1-DATE(ANNEE(A1);1;0)" que l'on étend à toute la nouvelle colonne (avec la date en colonne A). Cette formule permet de retirer au code de date (A1) le code du 1er janvier de l'année en question.
Ensuite, sélectionner ces quantièmes sur une année donnée (commencer par une année qui est complète, donc souvent pas la première du fichier), et les hauteurs sur la même période. Ensuite, insérer un graphe en "nuages de points". Si la colonne des quantièmes est à gauche de celle des hauteurs, ces jours seront en abscisse et les hauteurs en ordonnées automatiquement. Ensuite, faire "sélectionner des données", "ajouter" et sélectionner en abscisse les quantièmes d'une autre année avec ses hauteurs correspondantes en ordonnées (vous pouvez indiquer de quelle année il s'agit en 'nom de la série')
)
La série de courbes produite
Python
import pandas import matplotlib.pyplot as plt |
Importe la libraire Pandas, qui permet de lire le fichier
On va utiliser une autre librairie pour tracer |
infile = 'R_GARONNE_GARONNE_KM0163.txt' indata = pandas.read_csv(infile, sep=' ', skiprows=2, names=['date', 'heure', 'hauteur', 'erreur']) |
Le nom du fichier (entre ' ') Permet de lire et d'avoir en mémoire le tableau des données et ce de façon à pouvoir appeler ensuite les colonnes par un nom # le séparateur (sep) est un espace ',' # on saute les 2 premières lignes qui contiennent les en-têtes des colonnes (skiprows) # ensuite, on définit les noms (names) des différentes colonnes pour pouvoir les appeler ensuite |
indatavalid = indata[(indata['erreur'] < 9999)] |
Certaines mesures réalisées sont fausses ; une valeur de 9999 les indique. On ne garde que les lignes qui ne correspondent pas à cette valeur, et on stocke dans "intadatavalid". |
indatavalid['date-endate'] = pandas.to_datetime((indatavalid['date']), format='%Y-%m-%d') indatavalid['annee'] = pandas.DatetimeIndex(indatavalid['date_endate']).year indatavalid['dayofyear'] = pandas.DatetimeIndex(indatavalid['date_endate']).dayofyear |
Les données lues dans le tableau sont interprétées comme des chaînes de caractères, c'est-à-dire une suite de caractères (lettres, signes de ponctuation, chiffres…) ou éventuellement comme des nombres. Les dates et heures incluent des - et des : Ici, on ne va utiliser que la date (pas l'heure), et extraire l'année, ainsi que le numéro du jour dans l'année, pour servir d'abscisse (valeur commune à toutes les années, contrairement à une date complète). |
fig, ax = plt.subplots(figsize=(8,6))
for annee, groupe in indatavalid.groupby('annee'):
groupe.plot(ax=ax, x='dayofyear', y='hauteur', label=annee)
plt.xlabel("jour de l'année")
plt.ylabel("hauteur d'eau (m)")
plt.show()
|
On définit le tracé un peu différemment de plus haut, car on veut superposer les courbes des différentes années sur une même figure. Si on utilise la même instruction qu'avant, on a autant de figures que d'années. On va tracer par année (groupby('annee')) la hauteur (y) en fonction du numéro du jour dans l'année (x). La couleur des courbes est automatiquement sélectionnée. 'xlabel' et 'ylabel' permettent de nommer les axes. Label nomme les traits des différentes couleurs selon "annee". 'show' montre le tracé à l'écran. On pourrait le sauver dans un fichier. |
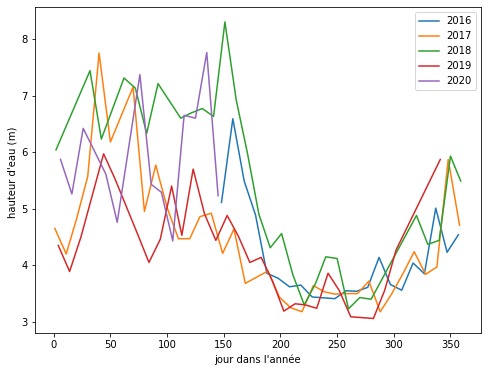
La série de courbes produite par ce programme
En regardant attentivement, on remarque qu'en 2017 (trait orange) le niveau était particulièrement haut en février (jours 32-59) et une partie de mars. 2018 (trait vert) a eu deux saisons très marquées : de 0 à 160 (janvier à mai) le niveau est très haut, avec un pic très élevé en mai, et basse les quatre mois suivants jusqu'au jour 280. 2020 (trait violet) a un pic en février, l'autre fin avril. Les différences en 2019 (trait rouge) sont beaucoup moins marquées. Les données de 2016 (trait bleu) ne commençant qu'en mai, on n'a pas de mesures en hiver ; on y observe cependant un pic vers le jour 160 (mai).
Conclusion
Cette analyse de mesures satellite sur un fleuve français peut être comparée à des stations "réelles" sur place, notamment celles qui servent pour le réseau d'alerte "vigiecrue" (https://www.vigicrues.gouv.fr/, ou des enregistrements à plus long terme de ces mêmes stations sur http://www.hydro.eaufrance.fr/). On obtient alors des mesures très fréquentes (toutes les quelques minutes), sur quelques fois des dizaines d'années, potentiellement même plus si des données anciennes ont été numérisées.
Les satellites de mesure de la hauteur sont plus spécialement utiles dans les cas où de telles stations n'existent pas, soit pour des questions de coût d'installation et de maintenance de la station proprement dite, soit parce que le terrain est difficile d'accès (forêts équatoriales, montagnes, zones peu habitées), ou les deux. Les satellites peuvent également fournir des données internationalement, rapidement et automatiquement, en particulier quand un cours d'eau traverse plusieurs pays qui ne coopèrent pas forcément étroitement. Les pays en aval peuvent être intéressés par les niveaux plus en amont, qui permettre de prévoir les hauteurs d'eau qui vont leur arriver.